A Failure Without Customer Impact. This Is Exactly Why Patrii Cloud Exists
Yesterday, we experienced an infrastructure failure on one of our compute nodes.
This kind of event happens. No serious operator pretends otherwise.
What truly matters is not trying to avoid every failure at all costs.
What matters is how the infrastructure reacts when it happens.
What happened
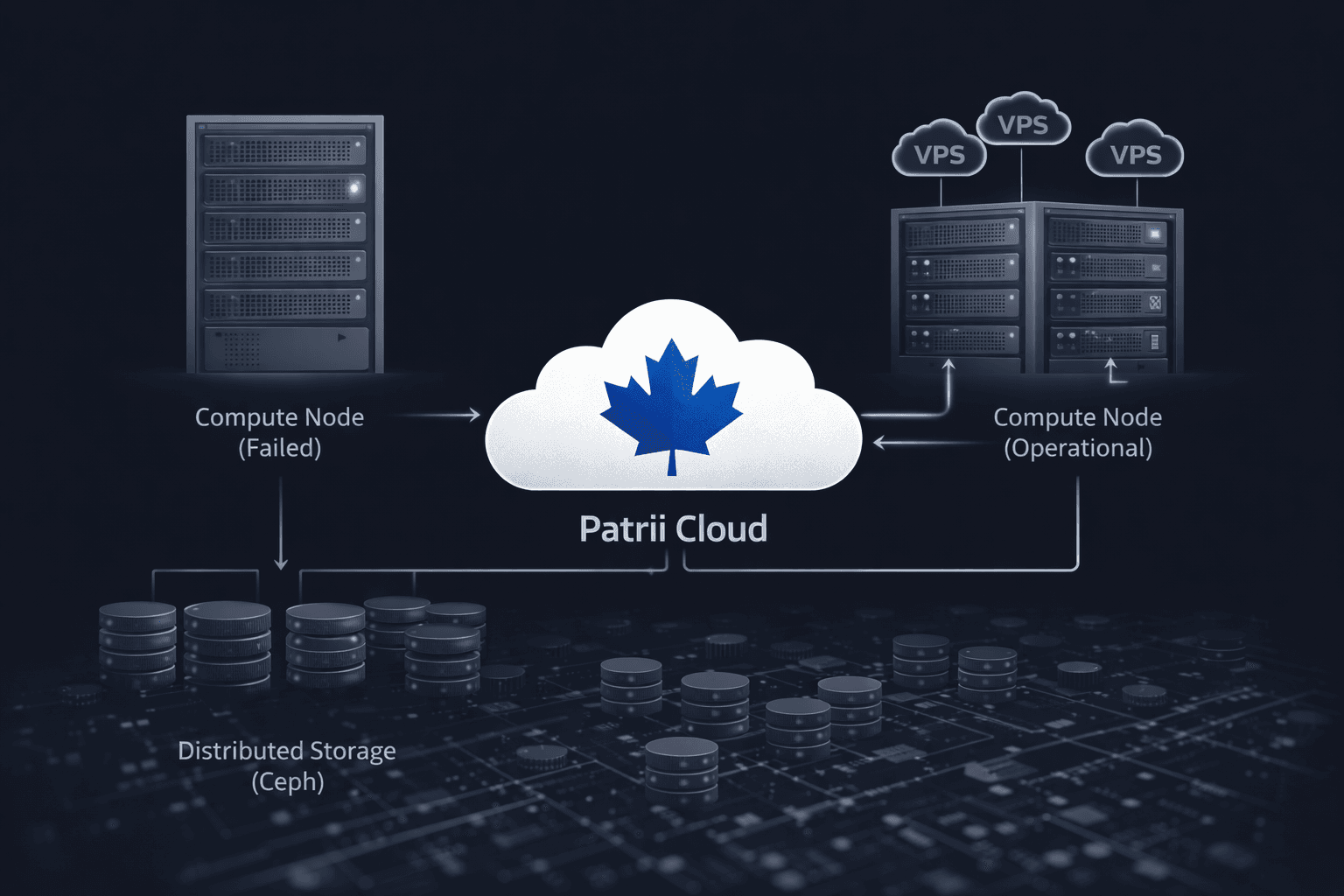
One of our compute nodes went down.
On a traditional infrastructure, this would usually mean:
- several minutes of downtime
- sometimes up to an hour of service interruption
- manual restarts
- customers waiting
- unnecessary stress
At Patrii Cloud, this scenario did not happen.
What our customers actually experienced
The VPS instances running on the failed node were instantly migrated to other healthy nodes.
Our orchestration system, combined with Vmoves, immediately:
- detected the failure
- recreated the full server definitions on other nodes
- restarted the instances automatically
In less than 10 seconds, everything was back online.
For the affected customers, it was as if nothing had happened.
No ticket to open.
No manual intervention.
No waiting.
Why this was possible
This behavior is not accidental. It is the result of deliberate architectural choices.
At Patrii Cloud, VPS storage is built on Ceph, a distributed storage system designed for resilience.
In practical terms:
- VPS disks are not tied to a single server
- data is distributed across multiple nodes in the cluster
- each block of data exists in multiple copies
- the loss of a single node does not result in disk loss
When the compute node failed, the VPS data was still fully accessible elsewhere in the cluster.
This allowed Vmoves to:
- instantly recreate servers on other nodes
- reattach existing volumes without manual reconstruction
- restart VPS instances almost immediately
Without distributed storage, this type of recovery is simply not possible.
This is not luck. It is an architectural decision
When we designed Patrii Cloud, we made a clear decision from day one.
We did not optimize for the easiest path.
We optimized for high availability.
That means:
- interchangeable compute nodes
- distributed, fault tolerant storage
- no dependency on a single physical server
- orchestration capable of rapid reconstruction
- resilience built directly into the platform
This kind of behavior cannot be added later.
It must be designed from the beginning.
Small today, built with the standards of large infrastructures
We may be small today, but we built our cloud with the same requirements as large scale infrastructures.
Size is not a measure of reliability.
Architecture is.
From the start, we chose to implement the mechanisms that allow a platform to remain stable over time, even when hardware failures occur.
What we are building is a solid foundation for:
- developers
- businesses
- critical workloads
- services that cannot afford downtime
Sovereignty also means reliability
A sovereign cloud has no value if it fails at the first hardware issue.
Sovereignty also means:
- the ability to react quickly
- full control over infrastructure
- transparency when incidents occur
- service continuity for customers
Yesterday, our infrastructure behaved exactly as it was designed to.
And events like this confirm that we are moving in the right direction.
Thank you to our customers for your trust.
We keep building, properly.
Your data. Your cloud. Your country.
The Patrii Cloud Team
Ready to get started?
Subscribe to our newsletter to stay updated with the latest news.
Start deploying on Patrii Cloud today!
Access Cloud Console